AI-Powered Document Processing
Turn unstructured files into structured metadata for workflow automation, dashboards, and analytics.
Transforming Documents into Actionable Data
For decades, organizations have accumulated massive stores of documents, such as purchase orders, HR files, incident reports, regulatory submissions, signed contracts, technical drawings, policy memos, and millions of emails. Much of this content is preserved simply as a byproduct of daily operations. In the past, these records might have filled a few filing cabinets, but now, storage footprints routinely stretch from on-premises servers to cloud archives, increasing from a few terabytes to multiple petabytes.
Despite the cost and effort involved in keeping these records, the critical information buried inside, such as contract expiration dates, approval signatures, incident descriptions, or key customer details, often remains inaccessible. Finding a specific clause or data point usually means searching through folders, opening files one by one, reading each document, and manually extracting the needed information.
This approach does not scale. For a large enterprise or agency that manages tens of millions of files across shared drives, email archives, and disconnected content management systems, it is nearly impossible to systematically extract, analyze, and use this data. As a result, your organization’s most valuable information, hidden within scanned PDFs, legacy Word documents, or old email attachments, remains dormant. This bottleneck prevents you from building live dashboards, triggering compliance reviews automatically, or supporting business intelligence systems that depend on granular, well-tagged data.
Feith’s AI-powered metadata extractor changes this process completely. It scans each document, identifies key entities and facts, and populates metadata fields, making your critical data accessible, actionable, and ready to drive downstream workflows.
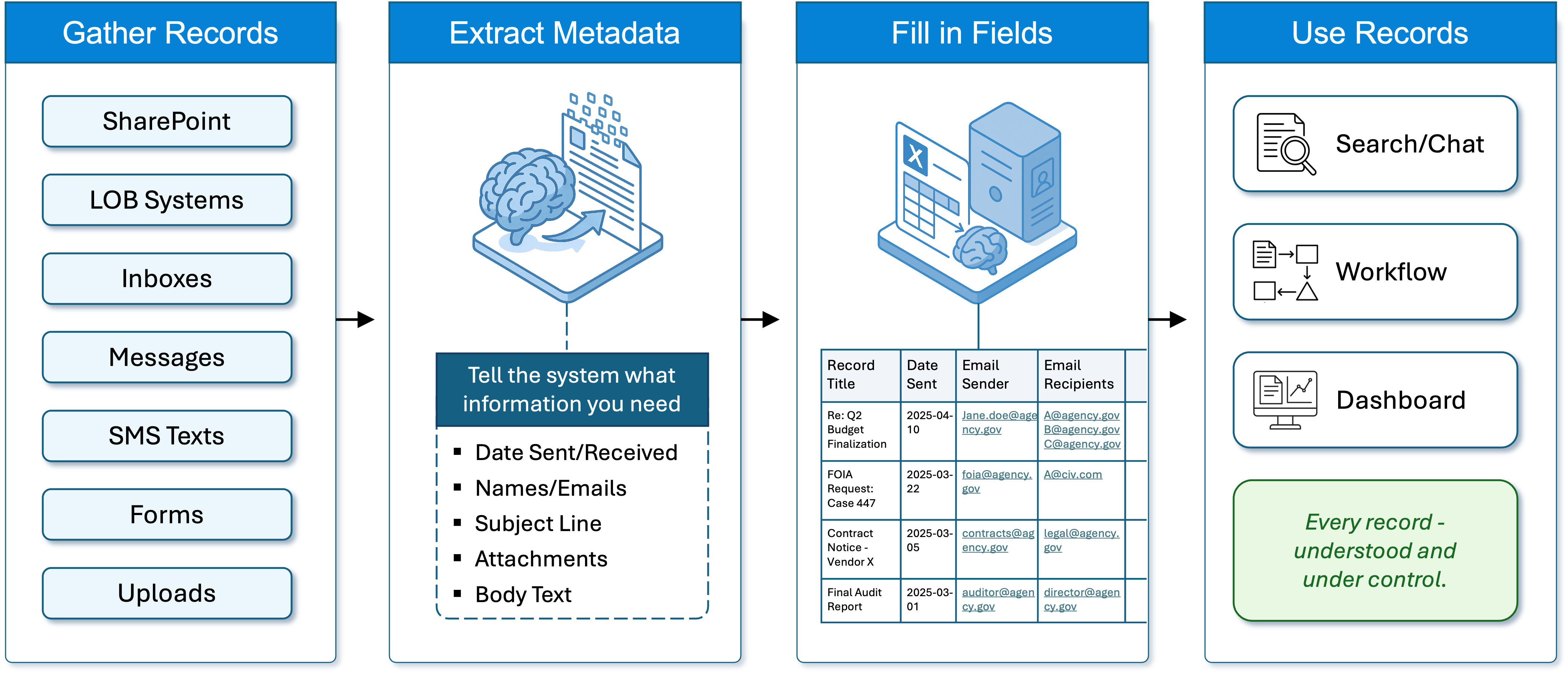
Introducing Feith's AI Metadata Extractor
With Feith, you do not need to rely on complex scripts or spend hours manually indexing documents as you would with older, pre-AI solutions. Instead, you simply tell the system in plain English what information you need to pull from a document or set of documents. For example, if you want to find out when contracts are set to expire, you just describe your request, such as “Find the contract’s termination dates,” and the AI takes care of the rest.
Once you provide your instructions, Feith scans every document in the selected repository or folder, quickly identifies the relevant data, and extracts the contract termination dates. You no longer need to open each contract or search through folders to track down this information yourself.
When key information is captured as metadata, whether it is contract dates, dollar values, approval signatures, or other important details, it becomes searchable, sortable, and ready for reporting or automation. You can set up reminders for critical deadlines, generate dashboards to track performance, and connect this information to your workflows and compliance processes. Now you’ve turned unstructured files into structured, actionable information.
Learn more about metadata extraction
Understands Context and Synonyms
Traditional indexing solutions have significant limitations. They only reliably extract information when it follows exact formatting rules or appears consistently in the same location within each document. For example, these tools might only recognize dates formatted as “03/15/2023” or located in a specific area on every page. Even then, they cannot automatically determine what that date represents, such as whether it is a submission date, incident date, or hire date. Any deviation in formatting, abbreviation, spacing, or placement typically causes traditional indexing methods to miss important information.
Feith’s AI-powered indexer addresses these issues by reading documents in a natural, context-aware way. It recognizes dates, names, dollar values, and other details across different formats, placements, and document types much like a human would.
Automatically Create Metadata Fields
After extracting the information, the AI automatically creates corresponding metadata fields in your database (e.g., “Training Completion Date”). It populates these fields across every relevant document and attaches the data precisely where it belongs.
This means you can quickly see who’s up to date, send reminders to anyone who’s overdue, and even generate visual summaries when you need an overview of the entire organization. Instead of wasting time digging through documents, you have consistent data that’s easy to use and keeps everyone on the same page. This approach not only reduces the chance of human error, but also helps your organization make better decisions based on accurate, readily accessible information.
AI Optimization for Every Environment
Scalability
Feith’s horizontally scalable architecture supports millions of documents and thousands of concurrent users across on-premises, private, or FedRAMP-compliant government clouds.
ROI
AI-driven automation reduces manual indexing tasks, freeing experts for high-value activities, while providing immediate, structured data critical for rapid, informed decision-making.
Security
Feith is committed to delivering zero‑hallucination, zero‑data‑leak AI. Every new capability stays in our controlled validation pipeline until it meets the criteria for use with federal data. Each release is then benchmarked against guidance from the U.S. Chief Data and AI Officer Council and other leading governance bodies.
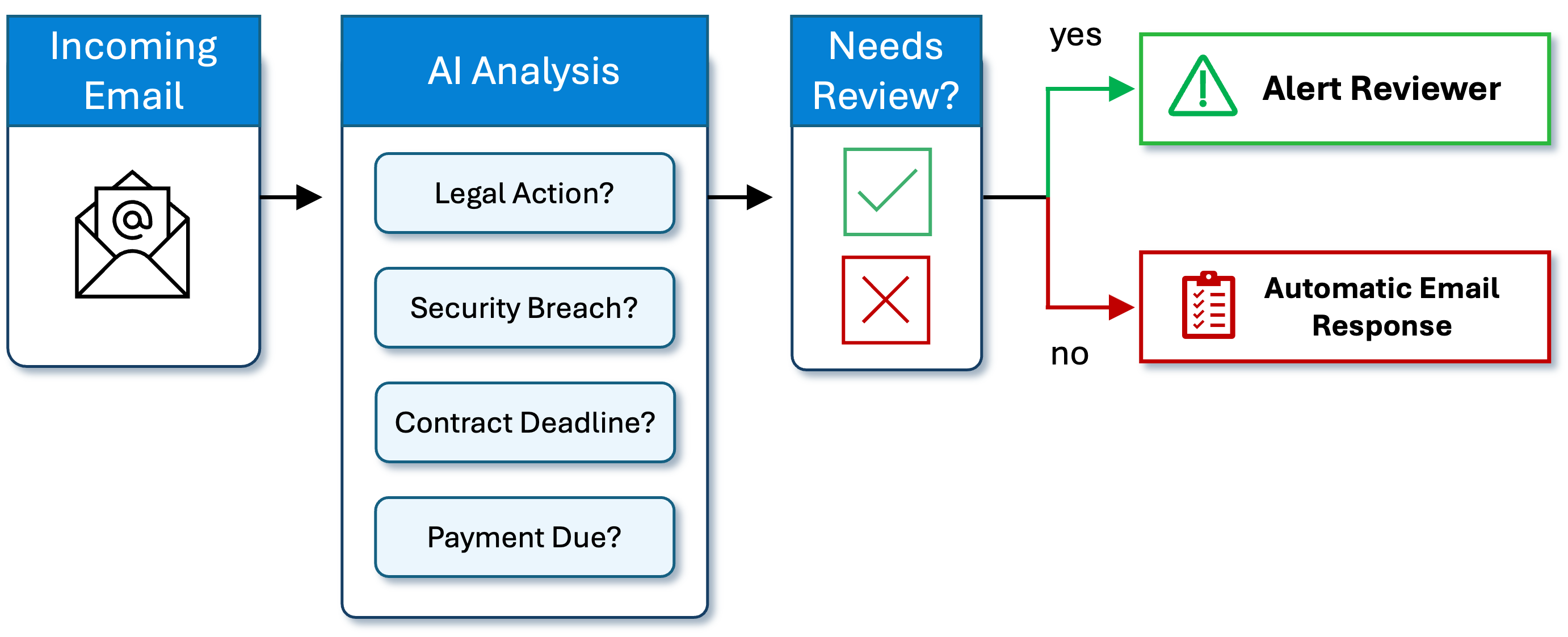
Smart Routing with AI-Extracted Metadata
Once AI extracts key metadata, that information can be used to drive smart routing decisions across your workflows or business processes. For example, in the case of incoming email, the system can detect indicators of legal action, security issues, payment status, or contract milestones, and route the message based on what it finds.
For example, messages that require attention can be escalated to a reviewer, while routine or low-risk content can trigger an automated response. This routing logic is driven entirely by the meaning of the content, not just by keywords or location on the page.
By using extracted metadata to classify and prioritize content, organizations can reduce the manual burden of triage, accelerate response times, and ensure that critical issues are handled promptly while routine cases are processed automatically. This same logic can be applied across a wide range of workflows, from case management and customer service to compliance and operations.
Analytics Powered by Extracted Metadata
Once metadata is extracted by AI, it can be aggregated, filtered, and analyzed just like structured data—making it immediately usable for dashboards and reports. This allows organizations to generate real-time visibility into operations that were previously hidden within unstructured content.
For example, if the AI identifies termination dates in contracts, due dates in invoices, or incident types in emails, that information can be charted and summarized across your entire repository. You can track trends in legal risk, monitor approaching deadlines, or generate compliance summaries without needing to manually review documents. Because the metadata is extracted directly from the content itself, the data is always current and tied to the source.
These dashboards and reports provide decision-makers with an up-to-date view of business activity, highlight areas that require attention, and support more accurate forecasting and resource planning. Instead of waiting for manual updates or relying on incomplete data, teams gain access to a live, document-aware reporting layer built from the actual content in their systems.